Language Lounge
A Monthly Column for Word Lovers
I Think We're All Bayesians on This Bus
This summer, as a consequence of a broken shoulder, I was unable to use my right hand on any keyboard for four weeks. This was a challenge since on average my written-word output on a given day is probably equal to or greater than what I say out loud. It was a desperate time and it called for desperate measures.
I'd dabbled with dictating texts to my phone instead of typing them on the tiny keyboard; my Android phone (I don't own or use Apple products) has a facility for this, and my tongue is quicker and more agile than my thumbs. On the computer keyboard, however, I had not explored voice input, or as it is fancifully called in the PC world, "Windows Speech Recognition." Working with these speech-to-text programs provided an opportunity to explore the challenges that this area of natural language processing (NLP) has yet to meet.
By now we're all familiar with some aspects of predictive language production; modern email clients (I use both Outlook and Gmail) will, if you let them, predict what you are about to type and display the text for you provisionally on the screen, which you can either accept (hit Tab) or reject (keep typing). I've written about this topic and its shortfalls in another article, The Low-Hanging Fruit of Predictive Writing. In a nutshell, these programs will steer you towards the safest bet, which is often a stale cliché, and also often far from what you mean to say.
A computer's ability to predict the next word you type is based on statistics. If you type the word foregone, it's pretty much a sure bet that the next word you type will be conclusion, because that collocation is about the only job we have these days for foregone. When a computer program has enough data to work with it can do Bayesian analysis—that is, make pretty good predictions about what will happen next, based on what has happened before. Bayesian analysis is named for the Reverend Thomas Bayes, who developed a theorem that the probability of an event can be calculated, or at least estimated, based on prior knowledge of conditions that might be related to the event.
The intuitive equivalent of Bayesian analysis is easy. Anything might happen at any moment, but the odds are that what does happen is something that has happened before, rather than something that has never happened. Bayesian analysis allocates credibility across a range of possibilities. Something that has happened before is given considerably more weight as a possibility than something that has never happened. And as it is in life, so it is in language: if it's been said before, odds are on that it will be said again. The more data you have to work with, the more confidence you can have in Bayesian predictions.
So here's what I was forced to ponder this summer: why is predictive typing so much more accurate and useful than predictive speech? The number and type of absurd errors that speech-to-text programs make seems quite anomalous when you compare it with the ever-increasing accuracy and dependability of predictive typing programs.
I suspect that the latter have the bandwidth to implement some form of Bayesian analysis, while the former do not. But it is probably also the case that if the computer is actually not sure of what you said in one sequence of phonemes or syllables, it's going to be very bad at predicting what the next sequence might be.
Here's an example: recently I was on my way to visit a relative in a hospital. Another family member was already there visiting. When I arrived at the light-rail station nearest the hospital and texted her that I was on my way, she asked whether she could pick me up. I said:
No, I'll bike up, I brought my bike with me on the train.
My phone interpreted this as:
No, I'll buy cup. I brought my bike with me on the train.
Admittedly, the pronunciation of the two sentences in flowing speech is identical. But the likelihood of the second sentence surely approaches zero.. No true-blooded Bayesian would think it possible. Why did my phone's text-to-speech program think it was correct?
The challenge here for speech-to-text systems is that they must recognize what is being said (as opposed to typed) in real time. The space bar on your computer gives any underlying interpretation program a very important clue: it tells the program that you are finished with that word. The program can then immediately perform several analyses: Is the word correctly spelled? Is it the right word in this context and not a homophone of the right word? Is it a part of speech that will work in this slot in the developing sentence? And finally, given the text so far, what is the greatest statistical likelihood for what will follow?
Our speech, on the other hand, has no easily recognizable space bars, and so speech recognition systems have to make their best guess about where words end. In this case, it seems as if the interpretation of my speech stopped as soon as phonemes constituting a word were recognized (the sequence /baɪ/, "buy"). Then the program is ready to analyze what comes next, which is the sequence /kʌp/, "cup". This would be a great time for the program to stop and ask itself: "does that actually make any sense?" But no, I'm still talking and the program has other work to do, interpreting what follows.
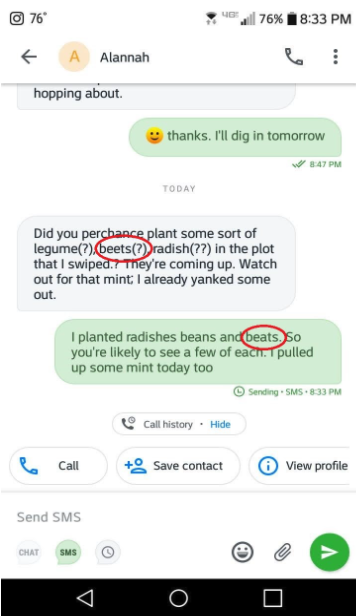
So here I'll cut the program some slack; there's clearly no facility in it for checking the sense of what has been output. Here's another example that I'm less forgiving of. This is a screenshot of a text conversation with my neighbor, a fellow gardener.
She has asked whether I might have planted some beets. I confirmed this, but unaccountably, the recognition program has deemed that I planted "beats". A homophone, yes. But no one actually plants beats! And beets, correctly spelled, just appeared in the previous text. So again here we see Reverend Thomas Bayes thrown out the window when it doesn't seem like it would be so great a challenge for the program to consider the current context and make a more likely interpretation of my speech sounds.
We're told that the arrival of 5G networks to our phones and other devices is going to surpass all the seven wonders. I hope that a small thing it will do is free up some bandwidth to bring a little more coherence to the interpretation of speech. Of course, once we hit the send icon, it's too late and the interpretation of our utterance, however faulty, enters the record of history. But there is much to be gained, in a Bayesian way, if speech-to-text programs can take a look at context and likelihood to determine what the speaker is actually saying.


