People judge you by the words you use. This warning, once the slogan of a vocabulary building course, is now the mantra of the new science of culturomics.
In "Quantitative Analysis of Culture Using Millions of Digitized Books" (Michel, et al., Science, Dec. 17, 2010), a Harvard-led research team introduces "culturomics" as "the application of high throughput data collection and analysis to the study of human culture." In plain English, they crunched a database of 500 billion words contained in 5 million books published between 1500 and 2008 in English and several other languages and digitized by Google. The resulting analysis provides insight into the state of these languages, how they change, and how they reflect culture at any given point in time.
In still plainer English, they turned Google Books into a massively-multiplayer online game where players track word frequency and guess what writers from 1500 to 2008 were thinking, and why. The words you use tell the culturonomists exactly who you are--and they can even graph the results!
According to the psychologists and mathematicians on the culturomics team, reducing books and their words to numbers and graphs will finally give the fuzzy humanistic interpretation of history, literature, and the arts the rigorous scientific footing it has lacked for so long.
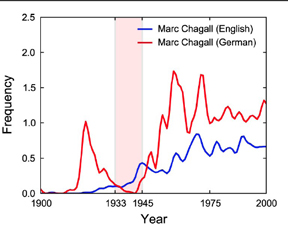
For example, the graph below tracks the frequency of the name Marc Chagall (1887-1985) in English and German books from 1900 to 2000, revealing a sharp dip in German mentions of the modernist Jewish artist from 1933 to 1945. You don't need a graph to correlate Hitler's ban on Chagall and his work with the artist's disappearance from German print (other Jewish artists weren't just censored by the Nazis, they were murdered), but it is interesting to note that both before and after the Hitler era, Chagall garners significantly more mentions in German books than he does in English ones.
One problem with the culturome data set is that books don't always reflect the spoken language accurately. When the telephone was invented in 1876, Americans adapted hello as a greeting to use when answering calls. Before that time, hello was an extremely rare word that served as a way of hailing a boat or as an expression of surprise. But as the telephone spread across American cities, hello quickly became the customary greeting both for telephone, and then for face-to-face, conversation.
Expanding the data set of written English to include not just books but also newspapers, periodicals, letters, and informal writing, as we find in the smaller, 400-million word Corpus of Historical American English, gives a better idea of the frequency of words like hello. But crunching numbers doesn't tell the whole story: we can infer from contemporary published accounts, many of them strong objections to the new term, that hello is much more common in speech than its occurrence in writing indicates.
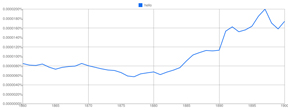
Above: Google book mentions of hello from 1860-1900 show a doubling of the word's frequency.
Below: the Corpus of Historical American English, despite its smaller database, tracks newspapers
and magazines as well as books, and gives a more accurate picture of hello: COHA shows a five-fold
increase in print mentions between 1860 and 1900.
It's one thing to read a book and speculate about its meaning—that's what readers are supposed to do. But culturomics crunches millions of books—more than the most ardent book club groupie could get through in a lifetime. Since most people have a hard time comprehending massively large numbers like five million volumes and 500 billion words, the researchers tell us that the words of the culturome laid end to end would form a string a thousand times longer than the human genome. And for fuzzy humanists who have no idea how long a genome is, they also compare the size of their data set to the distance from the earth to the moon: "If you wrote it out in a straight line, it would reach to the moon and back 10 times over" (your actual mileage may vary, depending on how big you make your letters, and where the earth and moon are in their orbits when you're measuring).
The culturome represents about 5% of the estimated 129 million books published since the invention of printing, and a third of the 15 million books digitized so far in Google's often controversial book project. For the math-challenged, that means if you have a library with 100 books, and you check out five of them, those five are your personal culturome. From those five books, the culturonomists make projections about what's in all the other books they haven't read, and that's a risky business.
The culturome can reveal small facts, like the frequency of Marc Chagall and hello, but it can also suggest the bigger picture. Preliminary analysis of the culturome tells us that English is growing faster than ever. It also gives an insight into cultural memory: we're remembering more but forgetting it sooner.
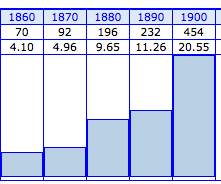
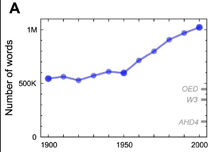
According to the culturome researchers, the English vocabulary doubled during the twentieth century, growing from 544,000 words in 1900 to a little over a million in 2000 (the culturonomists contribute to this lexical explosion by coining culturomics, along with its unit of measurement, the culturome).
The culturonomists define a word (they call it a 1-gram) as "a string of characters uninterrupted by a space." Maybe because lexicographers have a more rigorous idea of what a word is, our biggest dictionaries include only half as many words as the culturome. Dictionaries also reveal a different pattern of vocabulary growth. The OED has the number of new English words actually declining from 1950 to 2000, but the culturome shows a whopping 70% growth rate during that same period. In part that's because, to paraphrase Korzybski, the language is not the dictionary. For the culturonomists, "52% of the English lexicon—the majority of the words used in English books—consists of lexical 'dark matter' undocumented in standard references." But Google could be seriously over-counting words, since its book scan depends on optical character recognition rather than human readers, including forms like piblieh and frieude, OCR misreads of publish and friends, as strings of characters uninterrupted by a space. They may be dark matter, but no dictionary would count them as words.

Above: the OED timeline shows the greatest vocabulary spurt in English
occurring in the decades around 1900, while, below, the culturome
chronicles a 70% growth spurt in the second half of the 20th
century, much of it "lexical 'dark matter.'"
The culturome seems to indicate that a lot more happened in the second half of the twentieth century than in the first, and most of it isn't in the dictionary. What could generate more words than two world wars, the Great Depression, and the invention of the movies, radio, television, and the computer? After all, the 1950s saw the growth of a lexically-challenged, cookie-cutter suburbia, and no one was aware enough of 1960s to record its vocabulary. The 70's gave us Vietnam and bad hair, and the 80's, bad music, all of which can be summed up in very few words. But then came the 1990's and the birth of Google, a company that as recently as 2006 insisted that google was not a word. And after Google comes the vocabulary deluge, along with our new-found ability to count words--or strings of characters uninterrupted by a space--we never knew we had.
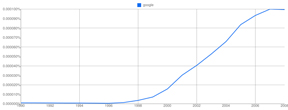
While graphs are nice, we don't need a culturome to
plot the rise of google from 1996 to 2008.
But despite debates about whether a big database gives more information than a small one, the culturome offers an important tool for the historical study of the written word. For example, we commonly suppose that the American spellings theater and center began replacing British theatre and centre in the 19th century, influenced in part by the American lexicographer Noah Webster, a patriot and spelling reformer whose Blue Back Speller was a popular school textbook. But the culturome gives a more complex picture of what actually went on: centre remains more common than center until 1900, while theater doesn't outperform theatre in America until the 1980s. Given that trend, it's surprising that we don't see any instances at all of Webstre for Webster.
As for cultural memory, tracking the names of well-known people in the culturome across time reveals that fame is now easier to come by than ever before, but it's also more fleeting: "The most famous people alive today are more famous—in books—than their predecessors. Yet this fame is increasingly short-lived: the post-peak halflife dropped from 120 to 71 years during the nineteenth century."
And speaking of the fickleness of fame, the culturome provides new opportunities for ego surfing. I say this because, yes, for some reason I'm in the culturome. My given name peaks around 1835, then goes into decline around the time I was born, and recovers only moderately since then. But my full name fares even worse, peaking ten years ago before entering a precipitous decline. This is a perfect example of the culturome researchers' conclusion that, "in the future, everyone will be world famous for 7.5 minutes."
Not that this is new information. Back in the 14th century, Geoffrey Chaucer didn't use statistics to prove that fame is hollow as well as fleeting. Chaucer recommended books, not graphs, to help us remember the past, but he also found books a great way to fall asleep. Today the new science of culturomics offers statistics as an even better cure for insomnia, a word which shows an alarming 300% increase in frequency since 1850.


