Language Lounge
A Monthly Column for Word Lovers
On Some Deficiencies in Our Search Engines
"Look it up!" used to be a directive mainly about words in dictionaries; these days it's as likely to be about information on the Internet. A common experience in both cases is that you don't always find what you're looking for. This month in the Lounge we look at some of the overlapping reasons why.
In the mid-19th century, British scholar Richard Chenevix Trench gave two papers that were later published as a booklet with the title "On Some Deficiencies in Our English Dictionaries." His observations were a major impetus for the work that eventually became the Oxford English Dictionary. Trench enumerated seven points that he considered the major failings of the English dictionaries of his day:

We like to think of the Internet as a more or less complete repository of information, and of a search engine as providing an index that enables us to access that information. But everyone who uses search engines finds them wanting, mainly in being unable to locate for us the information we seek (and that we "know" is there), or in returning to us information that was not what we sought.
Trench's main idea was that "A Dictionary . . . is an inventory of the language: much more indeed, but this primarily." The common theme of all his criticisms is that dictionaries fail as an inventory of the language, and while he uses the term inventory, his points suggest that what Trench really wants a dictionary to be is an index: an index in the Peircean sense (an idea we explored in the Lounge a year ago), in which the index is a genuine indication of its referent. If there is a change in the referent, there must be a corresponding change in the index for fidelity to be maintained. This is also what we want a search engine's index to be: complete, appropriately granular, and up-to-date, such that it will always point unambiguously and accurately to what is there on the basis of the indications we supply. Why doesn't it always work that way?
The reasons could fill, and probably have filled, a book. From our perspective in the Lounge, the interesting points have to do with precision and fuzziness, and the ways they are reflected in two fields that have everything to do with Internet searches and their results: logic and language.
Most of our searches employ a fuzzy tool (language) to retrieve a fuzzy object (information encoded in language). We have the opportunity to introduce some logical parameters into our search, via the various tools that Google and other search engines offer (there is a sample here), and once our search string is sent off to the engine, various algorithmic operations take place that employ logic. What comes back? If we are lucky and if we framed our search skillfully, we get just what we were looking for. But sometimes we don't, and the ways in which search engines fail us are analogous to the ways that dictionaries failed Trench: the dictionaries he criticized contained faulty information, or they did not contain words, or information about them, that he knew to be in the lexicon; our searches may fail to return information that is actually present online, or they may return information that is not a match, in every sense, for what we sought.
The reasons for these failures are also overlapping to some degree: the field of inquiry — all networked information, on the one hand, and the lexicon, on the other — are both constantly changing, redundant, highly ambiguous, not logically constructed, and contain innumerable asymmetrical relationships among their members (all of which give rise to what we are calling fuzziness). Constructing a perfect, failproof tool for access — an Internet index on the one hand, a dictionary on the other — is probably an impossibility.
It seems to us that a goal of a good search engine should be that the Principle of Least Astonishment prevails whenever possible: that is, given any ambiguity in our query or in the nature of the information we seek, we would like the search engine to be biased toward giving us what we want, rather than giving us something completely unexpected. There is ample documentation of cases where this principle fails: sites like Reddit and Digg regularly feature posts by people who got some (to them, anyway) astonishing and counterintuitive result from a simple or complex search. All search-engine users probably have an example of this sort in mind; in the Lounge, we have our own recurring faulty search result, which seems to be due to an error of logic brought about by ambiguity in language.
Our personalized Google News page has a section for stories associated with ZIP code 87901: the code for Truth or Consequences, New Mexico. Astonishingly, however, Google News consistently delivers stories to us that are not about this charming desert town at all, but that simply contain the phrase "Truth or Consequences" — a not uncommon journalistic trope. Here, for example, is a recent section from our personalized news page:
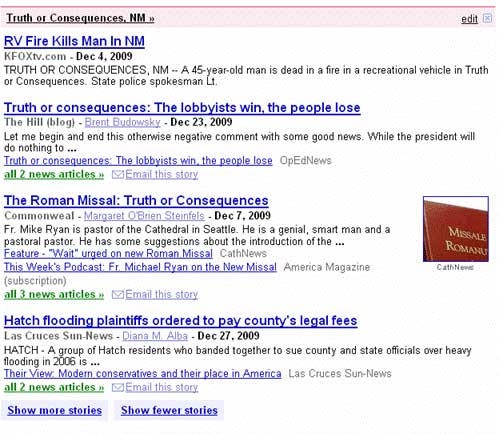
Of the four stories pointed to, two have nothing at all to do with Truth or Consequences, NM. This surely, is simply a logical error that cannot be difficult to put right: just as not every "87901" has to do with Truth or Consequences, New Mexico, not every "Truth or Consequences" has to do with a small desert town in the American Southwest. Is it beyond the ability of men and machines to correct this?
Trench made his observations about dictionary failings long before the wonders of modern information technology were even dreamt of. He, and those who responded to his challenge, used only the old-fashioned tools available to them; a plan for systematic and thorough research and synthesis of the lexicon, starting with a detailed analysis of how dictionaries imperfectly reflected it. Modern crafters of search engines have the advantage of programming languages and lightning-fast computation, but in some ways have still not overcome basic challenges. We wonder if a closer examination of search engines failures, using the same old-fashioned tools available to Trench and his followers, might prove to be a fruitful avenue for search engine improvements.


